
In my previous post, I set up a simple paste bin app on a local Kubernetes cluster using Kind. Building on that experience, I’ve now turned my attention to hosting Ollama; a tool to run large language models locally. There is also a good web front end for it called openweb-ui
I need both of these tools as I use Ollama API’s in some python scripts and Openweb-ui when I need to search something.
For deploying these two tools on k8s, the manifest looks like
apiVersion: apps/v1
kind: Deployment
metadata:
name: ollama
spec:
replicas: 1 # Number of replicas
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
containers:
- name: ollama-container
image: ollama/ollama:latest
ports:
- containerPort: 11434
env:
- name: OLLAMA_HOST
value: "0.0.0.0"
volumeMounts:
- name: ollama-vol
mountPath: /root/.ollama
volumes:
- name: ollama-vol
persistentVolumeClaim:
claimName: ollama-claim-vol
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ollama-claim-vol
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Service
metadata:
name: ollama-service
spec:
selector:
app: ollama
ports:
- protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: openweb-ui-deployment
labels:
app: openweb-ui
spec:
replicas: 1
selector:
matchLabels:
app: openweb-ui
template:
metadata:
labels:
app: openweb-ui
spec:
containers:
- name: openweb-ui
image: ghcr.io/open-webui/open-webui:main
ports:
- containerPort: 80
resources:
limits:
memory: "512Mi"
cpu: "500m"
volumeMounts:
- name: webui-volume
mountPath: /app/backend/data
volumes:
- name: webui-volume
persistentVolumeClaim:
claimName: open-webui-pvc
---
apiVersion: v1
kind: Service
metadata:
name: openweb-ui-service
spec:
type: NodePort
selector:
app: openweb-ui
ports:
- protocol: TCP
port: 8080 # Port exposed by the service
targetPort: 8080 # Port exposed by the container
nodePort: 31800
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
app: open-webui
name: open-webui-pvc
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 2GiIn this manifest, we are configuring following
- a service for Ollama which runs on node port
31434 - a service for Openweb-ui which runs on node port
31800 - a
PersistentVolumeClaimfor Ollama to store model files - a
PersistentVolumeClaimfor Openweb-ui. - a container for Ollama
- a container for Openweb-ui
To deploy this
kubectl apply -f ollama.yamlOnce this is deployed, you get the front end running on the node port 31800.
To get the node IP, (same as the previous post) run,
girish in ~ as 👩💻
🕙 02:34:27 ❯ kubectl get nodes -o wide | awk -v OFS='\t\t' '{print $1, $6, $7}'
NAME INTERNAL-IP EXTERNAL-IP
kind-control-plane 172.18.0.2 <none>
To access the front end, visit http://172.18.0.2:31800
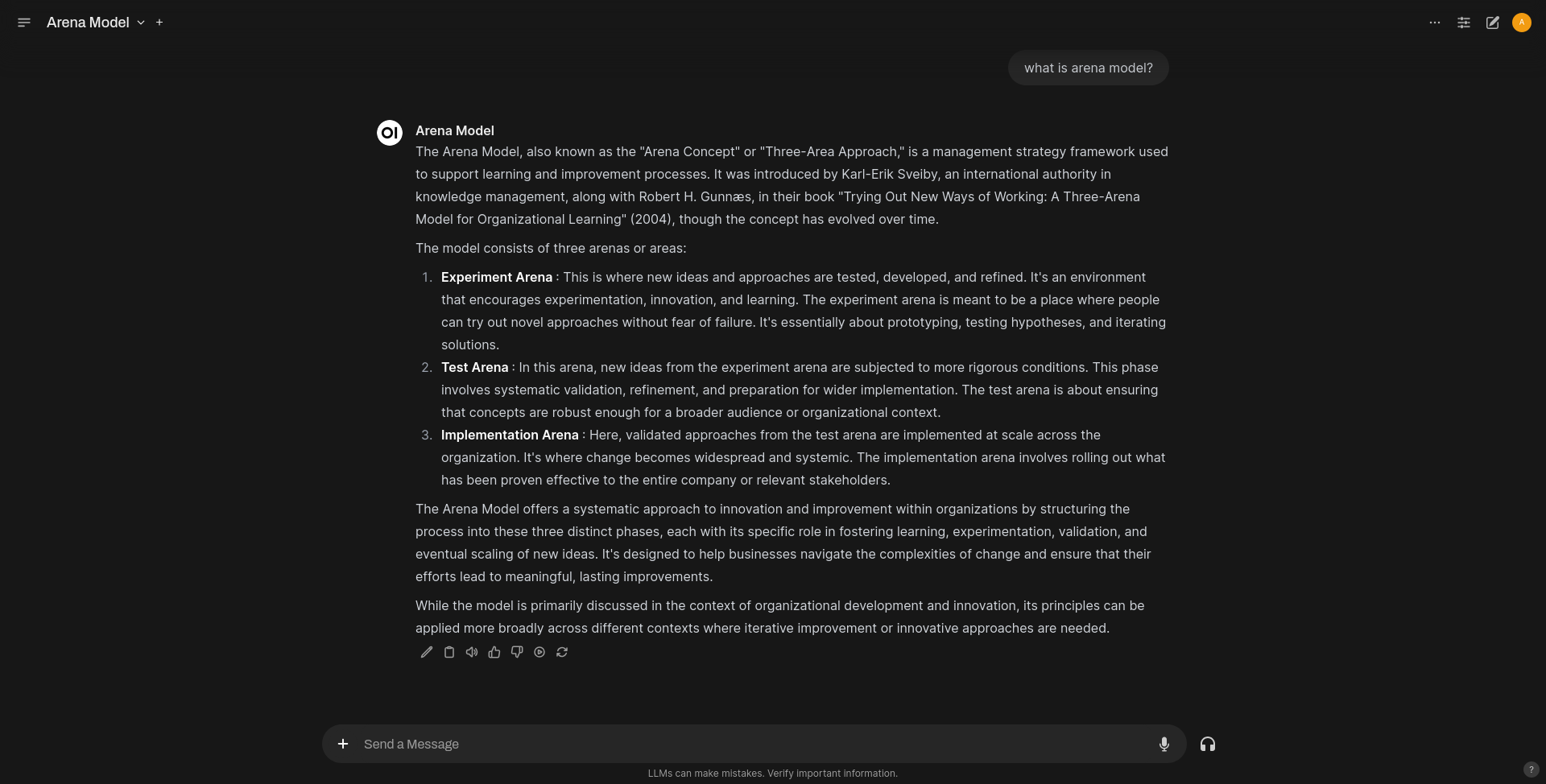
As you can see, we still need to access it from a nodePort.
Which means we need to port forward to use it from other devices on the network.
To fix this I have implemented a proxy. I’ll talk about it in the next post.